
Kesalahan Umum Analisis Kombinasi PSM-DID dengan Data Repeated Cross-sectional
🔥 Jangan Lewatkan: Kelas Social Media Data Analytics Batch 38 🚀
Tanggal: 16 June 2026 | Investasi: Hanya 350k! 🌟
Gabung sekarang dan tingkatkan keterampilan Anda dengan praktisi terbaik! 📊💡 Daftar Sekarang 🔗
Pendahuluan
Mengapa analisis kombinasi PSM-DID menjadi pilihan utama dalam penelitian sosial dan kebijakan? Sederhana saja, metode ini sangat kuat untuk mengatasi bias seleksi sekaligus menangkap efek kausal. Tapi, apakah metode ini bebas dari kesalahan? Tentu tidak! Banyak peneliti sering kali membuat kesalahan umum yang dapat merusak validitas hasil. Artikel ini membahas kesalahan-kesalahan tersebut dan cara menghindarinya.
Konsep Dasar PSM dan DID
Apa Itu Propensity Score Matching (PSM)?
PSM adalah metode yang mencocokkan unit treated dan control berdasarkan skor probabilitas mendapatkan perlakuan. Dengan ini, kita bisa memastikan bahwa perbandingan dilakukan secara adil, seperti membandingkan apel dengan apel, bukan apel dengan jeruk.
Apa Itu Difference-in-Differences (DID)?
DID digunakan untuk membandingkan perubahan hasil antara kelompok treated dan control sebelum dan sesudah perlakuan. Metode ini sangat baik untuk mengontrol faktor tetap yang tidak teramati selama waktu tertentu.
Peran Data Repeated Cross-sectional
Data repeated cross-sectional berbeda dengan data panel karena sampelnya tidak sama di setiap periode. Data ini sangat berguna untuk evaluasi kebijakan ketika pelacakan individu tidak memungkinkan. Namun, penggunaan data ini juga memiliki risiko jika tidak dilakukan dengan benar.

Kesalahan Umum dalam Analisis PSM-DID
Tidak Memvalidasi Asumsi Tren Paralel
Asumsi tren paralel adalah jantung dari analisis DID. Banyak peneliti gagal memeriksa apakah tren hasil sebelum perlakuan serupa antara kelompok treated dan control. Jika asumsi ini tidak terpenuhi, hasil analisis bisa menjadi bias.
Kesalahan dalam Estimasi Propensity Score
Kadang-kadang, variabel yang tidak relevan dimasukkan dalam model estimasi, atau model yang dipilih tidak sesuai. Ini seperti menggunakan peta yang salah saat ingin mencapai tujuan—hasilnya pasti melenceng!
Mengabaikan Balancing Covariates
Salah satu tujuan PSM adalah memastikan covariates seimbang antara kelompok treated dan control. Namun, jika balancing test diabaikan, analisis menjadi kurang valid.
Salah Memilih Metode Matching
Pemilihan metode matching, seperti nearest neighbor atau kernel matching, harus disesuaikan dengan karakteristik data. Salah memilih metode bisa mengurangi akurasi estimasi.
Artikel Blog Sekolah Stata di indeks Oleh Google Scholar
Akses Google Scholar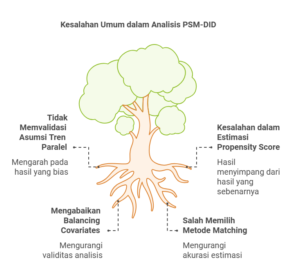
Implementasi yang Tepat dalam Analisis PSM-DID
Langkah Meminimalkan Kesalahan Umum
- Validasi Asumsi Tren Paralel: Gunakan visualisasi dan tes statistik.
- Estimasi Propensity Score yang Akurat: Pilih model yang tepat seperti logit atau probit.
- Lakukan Balancing Test: Pastikan distribusi kovariat seimbang antara kelompok treated dan control.
Contoh Penggunaan yang Baik
Sebuah penelitian berhasil menunjukkan dampak kenaikan upah minimum menggunakan kombinasi PSM-DID. Peneliti memvalidasi asumsi tren paralel, mencocokkan unit dengan kernel matching, dan melakukan balancing test secara menyeluruh.
Studi Kasus
Desain Penelitian dan Data
Penelitian ini menggunakan data survei tenaga kerja dua periode (2018 dan 2020) untuk mengevaluasi dampak pelatihan kerja. Kelompok treated terdiri dari pekerja yang mengikuti pelatihan, sedangkan kelompok control adalah mereka yang tidak mengikuti pelatihan.
Hasil dan Analisis
Hasil menunjukkan peningkatan signifikan dalam tingkat upah pekerja yang mengikuti pelatihan. Dengan validasi asumsi tren paralel dan balancing test, estimasi efek perlakuan dapat dipercaya.
Kesimpulan
Kombinasi PSM-DID adalah metode yang kuat, tetapi hanya jika digunakan dengan benar. Kesalahan seperti tidak memvalidasi asumsi tren paralel atau mengabaikan balancing test dapat merusak validitas hasil. Dengan perhatian terhadap detail dan implementasi yang cermat, metode ini dapat menghasilkan estimasi kausal yang andal.
FAQ
1. Apa yang terjadi jika asumsi tren paralel tidak valid?
Hasil analisis menjadi bias, sehingga perlu menggunakan metode lain seperti Synthetic Control.
2. Bagaimana cara memastikan covariates seimbang?
Lakukan balancing test menggunakan uji t atau regresi untuk memeriksa perbedaan rata-rata kovariat.
3. Apakah semua data cocok untuk PSM-DID?
Tidak semua data cocok. Pastikan ada kelompok control yang relevan dan covariates yang memadai.
4. Apa metode matching terbaik untuk PSM?
Metode terbaik bergantung pada data Anda. Kernel matching biasanya lebih fleksibel dibanding nearest neighbor.
5. Apakah software lain selain Stata dapat digunakan?
Ya, R dan Python juga memiliki paket untuk PSM-DID seperti MatchIt atau causalimpact.